

Seeing Is Believing: Visualizing Legal Research

A quote I always use when I’m teaching statutory research is, “Statutes are not cuddly, and no one reads them for fun.”[1] The legal profession relies primarily on the written word, and those words typically aren’t light bedtime reading. Legal research, when compared to other mandatory text-dense courses, can offer a reprieve. As a practical course it is often rooted in processes that benefit from visual aids.
This post will provide an overview of some visual aids for teaching legal research that I’ve developed over the past few years. I share these based on positive student feedback and with the hope that others might find them useful in their own teaching or training.
These visuals have been removed from their original presentations and made uniform in their design. To reduce the number of images in this post, information originally shown on multiple slides has been combined. As a result, I have added text to the images and provided written descriptions to attempt to address any lost context. I hope these adjustments do not detract from the visuals overall. These are shared under a CC BY-NC 4.0, primarily for the NC component. Please remix, adapt, and build upon these materials.
Integrating Generative AI into the Legal Research Process
Generative AI is now embedded in all three major legal research platforms. I understand the temptation to begin a search using these tools, particularly if a written hypothetical or clear fact pattern is provided. However, regardless of where the legal research process starts, generative AI can only supplement the existing legal research process. Traditional methodology and legal research skills are still essential. This visual displays points where generative AI can be integrated into the legal research process as an assistive tool.
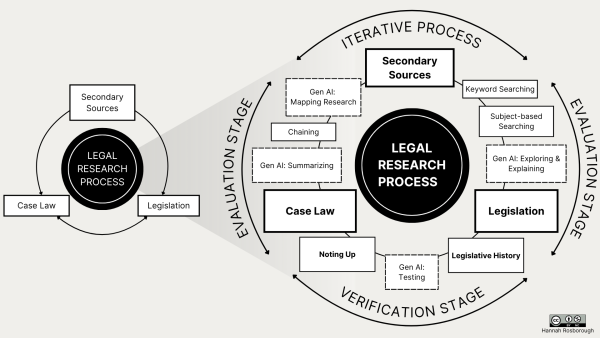
The expanded legal research process highlights where the essential processes of evaluation and verification must occur, and maintains essential skills like subject-based searching, noting up, and completing a legislative history. This is meant to communicate that a researcher can flow back and forth between generative AI and traditional techniques and tools during their research process.
Another goal is to visualize the reality that incorporating more research techniques and tools doesn’t always streamline research. It’s a busy image! Adding generative AI to the research process may take longer than using a traditional skill, like simply checking a case digest or noting up a section of a statute. It’s a reminder to always pause and ensure the research techniques and tools being applied match the research task, rather than force the task to fit a generative AI tool. It might save a lot of time.
*Note: There are lots of skills omitted from this visual. It is not comprehensive.
Impact of Generative AI Overreliance
Following retrieval of sources using a legal research platform, a researcher critically evaluates their evidentiary value and application. Drafting is the point where a researcher’s synthesis of different perspectives, approaches, and interpretations is communicated in their analysis. This visual encourages researchers to remember that research and writing, while they can overlap, are utimately two distinct processes with their own unique value.
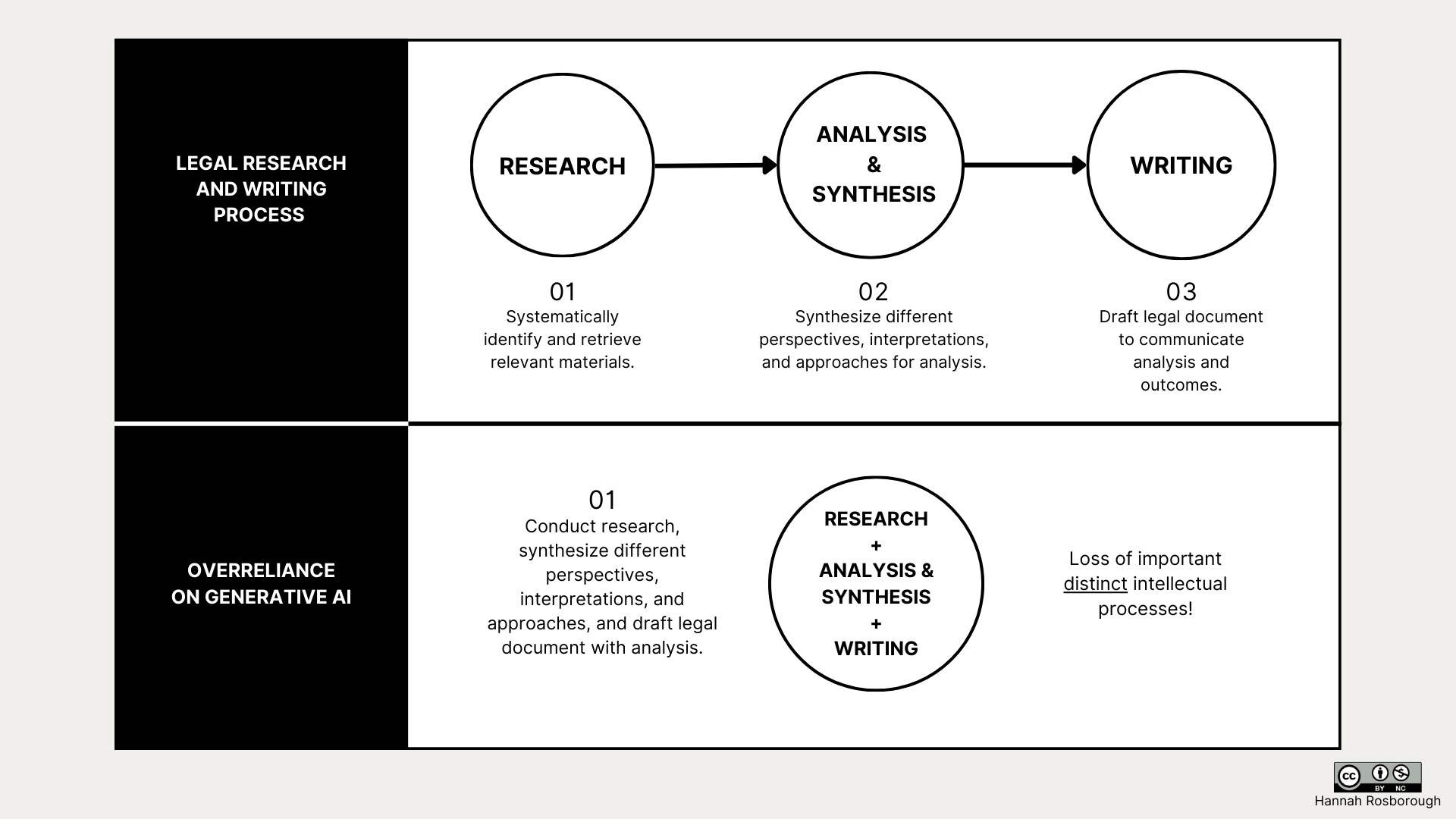
[ Figure 2. Impact of Generative AI Overreliance ]
In summary, supporting the idea that generative AI is an assistive tool to supplement the traditional legal research process, relying heavily on generative AI early in the research process can alter source selection and knowledge synthesis and interpretation. Overreliance removes the researcher from valuable intermediary intellectual processes where knowledge and understanding are built, tested, and refined. Avoiding overreliance on generative AI and engaging in the research process will help you develop a deeper understanding of the law and develop stronger legal arguments.
Boolean, Plain Language, and Prompting
Plain language searching did not render Boolean useless, and generative AI hasn’t replaced either of the former techniques. Generative AI has provided another search technique that a researcher can add to their repertoire once they understand how to use it effectively. This visual attempts to flag the differences in how results are retrieved and displayed with each search technique and open a discussion about how that might impact subsequent interpretations and analysis.
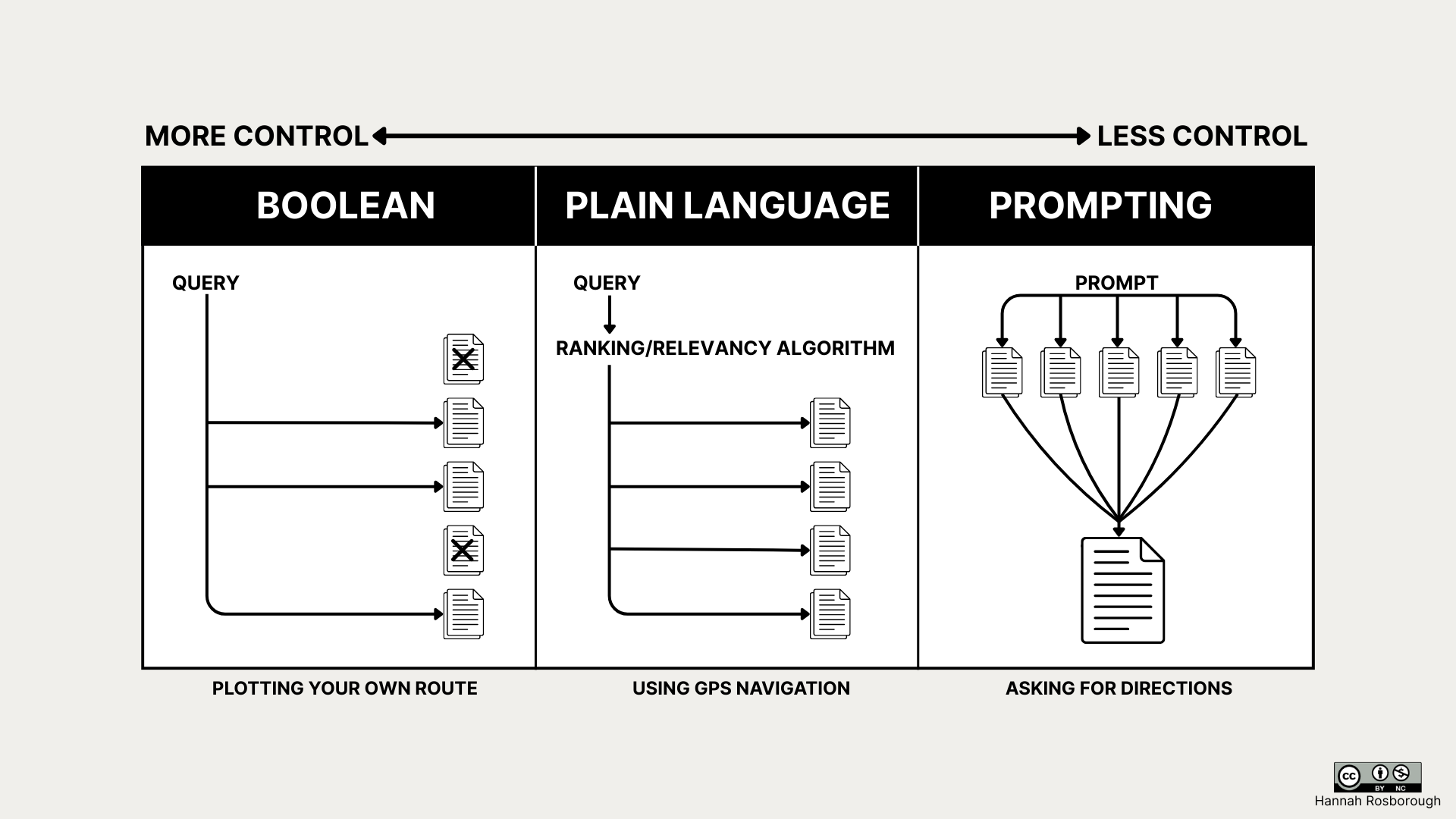
[ Figure 3. Compare and Contrast: Boolean, Plain Language and Prompt Search Techniques ]
Underlying this approach is the assumption that there is a finite, identifiable collection of documents that can be filtered and navigated through with deliberate choices. This reflects a very different research psychology than using generative AI. Boolean searching is grounded in the idea that legal knowledge is built through locating and engaging with sources themselves. Boolean emphasizes precision, transparency, and reproducibility. It is, however, a more technical skill.
Plain language provides control over the query, but the search engine determines which terms are most important, expands concepts using synonyms or related terms, and ranks results based on relevance signals. Results are ordered by likelihood of relevance to terms and, because the system makes minor transformations to the query, the exact reasoning behind result ranking may be opaque and vary between platforms. Plain language searching is quicker and more accessible than Boolean, but slightly less transparent, precise, and reproducible.
Prompting offers the least control of the search methods covered. The entire prompt is interpreted through inferring semantic context between words using probabilistic language modelling. The model predicts a response based on its training data, parameters, and retrieval augmented generation (RAG) if available. Legal research platforms that use RAG do surface hyperlinked citations, but only some models expose their reasoning steps, making it difficult to understand and impossible to reconstruct how the tool moved from prompt to output. On top of this, the non-deterministic nature of generative AI means that the same model, given the same prompt, will produce a different response each time. Compared to plain language or Boolean searches, prompting offers significantly lower transparency and reproducibility.
Generative tools can produce an endless stream of new interpretations or syntheses of those sources. The onslaught of information can distract from the value of a structured Boolean search, because it moves attention away from discovering and evaluating documents and toward consuming generated interpretations of them. This subtly reframes the source of legal knowledge as the analysis generated about sources of law rather than the sources of law themselves.
It’s important to consider that the UI and UX of LLMs will change as this area develops and this visual may need to be adjusted. For example, the new CanLII Search+ tool generates a Boolean query as a response to a prompt instead of a narrative or analytical response and explains the reasoning for the construction of the query. CanLII maintains the standard results page, making the research transparent and reproducible. I think this is an excellent, effective amalgamation of techniques and tools.
I’ve also tacked on an imperfect analogy at the bottom of this visual (because apparently I think research and transportation have a lot of overlap). Boolean is like plotting out the exact coordinates of the route before a trip begins. Plain language is plugging your start point and end point into Google Maps: You are a passenger along for the ride guided by an algorithm. Prompting is like asking someone for directions: You’ll likely get to your destination, but the conversation is unlikely to be repeated verbatim and you don’t know whether the person has deep knowledge of the area or they just gave you their best guess.
Practitioner vs Scholarly Legal Research
Law students come from many different academic disciplines and possess a range of credentials. Their familiarity with writing a major paper (legal essay, scholarly article, etc.) varies greatly. At the Schulich School of Law, our first-year Legal Research and Writing (LRW) course focuses largely on practitioner research and writing, relying on the legal research process of using secondary sources to find and understand the law. When students are required to write a mandatory major paper in their second and third years, some default to the standard legal research process taught in LRW. While there are transferable skills between practitioner and scholarly research, there are also key differences. This visual compares the standard practitioner legal research process to a flow chart of a simplified scholarly research process to flag some of those differences.
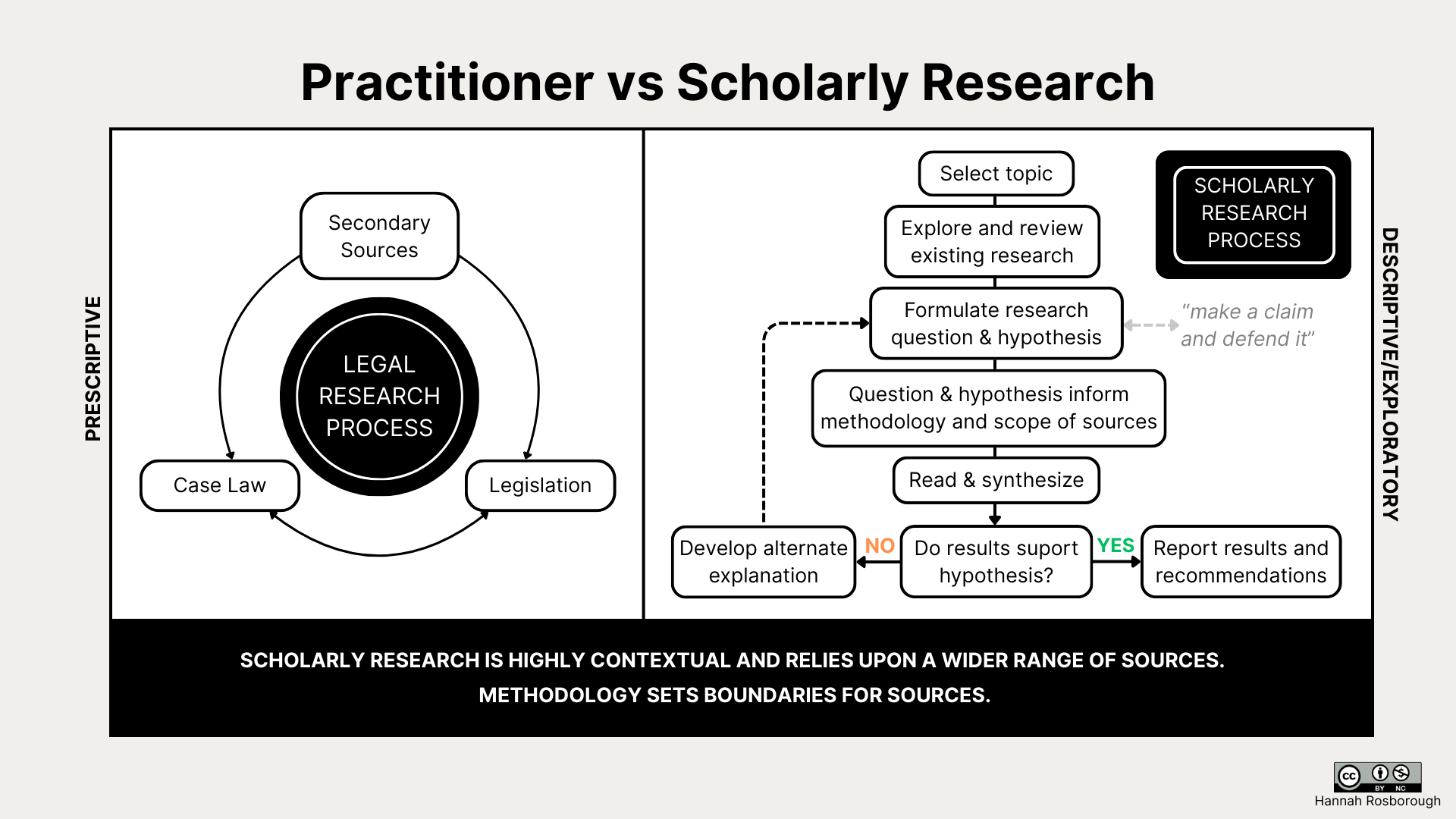
[ Figure 4. Practitioner Legal Research vs Scholarly Legal Research ]
It also notes the difference between prescriptive legal writing and more descriptive, exploratory scholarly writing. Prescriptive legal writing tells the reader what rules apply to a set of facts and, depending on the document type, persuasive arguments about the application of the law. Both types of writing evaluate options, develop arguments, and consider policy implications, but scholarly writing does so in a descriptive way. Scholarly writing uses more reflective and exploratory perspectives to observe and examine patterns or evidence to understand the law and suggest recommendations for consideration.
Legal Citation as a Unique Style
To end on a lighter but appropriate note, since legal writing must reference authorities, I will conclude with legal citation. In a decade of teaching, I have yet to meet a student who arrived at law school excited about legal citation. Most have never heard of it and, quite reasonably, many wonder why they need to learn an entirely new citation style. To explain, I use a visual that analogizes legal citation with bread.

[ Figure 5. Why Legal Citation is Unique ]
Citation styles work the same way. Different disciplines rely on “default” sources and methods. Engineers cite standards, conference papers, and datasets, so their citation systems are designed for those materials. Law revolves around cases, legislation, parliamentary debates, policy documents, etc., and its citation style is designed to communicate these sources effectively.
Bread traditions are not just cultural preferences, they developed because certain breads worked best based on the available materials and methods. Citation styles have evolved in much the same practical way.
Final Notes
I hope these visual aids can be helpful for training and teaching about legal research processes, techniques, and tools. Or, at the very least, maybe they can be a break from 12-point Times New Roman.
____________________
[1] Arlene Blatt & Joanne Kurtz, Legal Research: Step by Step, 5th ed (Toronto: Emond, 2020) at 17.

To add a bit of relevant context here, Hannah is the winner of the 2026 Schulich School of Law Teaching Excellence Award! Congratulations Hannah!
Thank you for this, Hannah! I am just sitting down to re-work my summer student training slides, and was procrastinating because I didn’t know how to incorporate AI. This is a perfect starting point!
Thanks so much, Hannah! I am also about to update my summer training slides, and these are extremely helpful diagrams!
Congratulations, Hannah! Very well-deserved!!
Consider this (semi-on-topic):
Writing laws like writing programs, except you’re limited to the universal quantifier ∀x P(x), and one or two global variables.
This is great!
Thanks for all the kind comments, folks! It’s always nice to know someone is actually reading my posts!
This is an absolutely fantastic post! Kudos!
This post was a great pleasure to read. Love the graphics and analogies.
Fantastic work, Hannah!