

“It’s Not Information Overload. It’s Filter Failure.”

Clay Shirky, way back in 2008, had a hypothesis: that it isn’t a case of too much information; it’s that we haven’t yet got the filters to help us manage that overload.
And we have to assume that the amount of information we’re already getting will continue to grow. Which is not necessarily a bad thing. But, if we are to deal with that firehose aimed at our brains, we need to get smarter; because if we don’t we’re just going to get wetter.
When looking for recommendations of where to eat in a new city, for example, where do you turn? Google? “Best-Of” reviews and Foodie accounts? Or perhaps friends and colleagues on FaceBook or Twitter? Or your old-school, well-worn travel guidebooks? We know that typing ‘restaurants London’ into Google is going to give us a firehose of results (yep, as it turns out, about 365 million results). We therefore turn to our filters to help sift this ridiculous number down to a more manageable set of options that we can reasonably choose from. One tactic for filtering out the noise might be to only look at the first page of Google results. Another tactic might be to narrow the location of your search to those cool neighbourhoods you’ve heard about in London. Stoke Newington or Dalston for example. Or to a set of restaurants you know you’ll enjoy. Like the range of Michelin 2- or 3-starred restaurants. Or just Spanish restaurants. Anyway, you see what I’m getting at.
Of course, the more popular a document or site or restaurant is, the easier it is to find. Our world continues to define filters for us based on popularity. Sometimes they are a great indicator of quality, sometimes not. Think of the Booker Prize short-list, Hollywood’s Box Office Mojo, Billboard’s top 100 charts, TripAdvisor’s Top 25 destinations, and so on. With so much noise out there – so many movies, so much music, too many books to read in one’s lifetime – it can be a blessing to base your decision on the formula of that-many-people-can’t-be-wrong. But all of that is changing. There is now a new demand for more niche products and services.
The same is true in our firms: by using search and document analytics we can tell what’s popular and what’s not. And we can create best bets or other guided filters to help make these documents easier to find. However, the wildly different informational needs of lawyers and their practices end up creating an overwhelming majority of unique retrieval requests. Lawyers aren’t necessarily looking for the most popular; niche deals and matters often have us looking for just a single document or expert. And it’s in these niche areas where connecting lawyer to document becomes harder, and the need for more filters becomes essential.
As Chris Anderson of The Long Tail wrote about long ago – we’ve gathered around us a reliable set of filters to manage this firehose of information out there on the Web:
“These technologies and services sift through a vast array of choices to present you with the ones that are most right for you. That’s what Google does when it ranks results: it filters the Web to bring back just the pages that are most relevant to your search term.” (from the brilliantly titled Chapter 7: “Filters Rule”)
So what is the Long Tail?
One Amazon employee defined the Long Tail like this: “We sold more books today that didn’t sell at all yesterday than we sold today of all the books that did sell yesterday”. And yes, that does take a minute or two of furrowed brow to get any sense from that.
Perhaps a diagram will help:

Otherwise: head over to Wired and read Chris Anderson’s popular article that spawned the book.
The traditional retail economics of every CD, DVD and book needing to earn its shelf-space by being sold more than once or twice a quarter went out the window in the move online. Suddenly it didn’t matter that a DVD or book was selling so poorly compared to their mass-market alternatives. In fact, Amazon and Netflix etc have been able to turn those niche products that sit in the long tail into big business. While they still only sell in small numbers, it is in the aggregate that these niche products create their very own tidy profit.
This type of curve is called a “power law graph” and can also be found when we analyse those search statistics of our Enterprise Search systems. Below is a typical distribution curve showing the frequency (or not) of search queries:
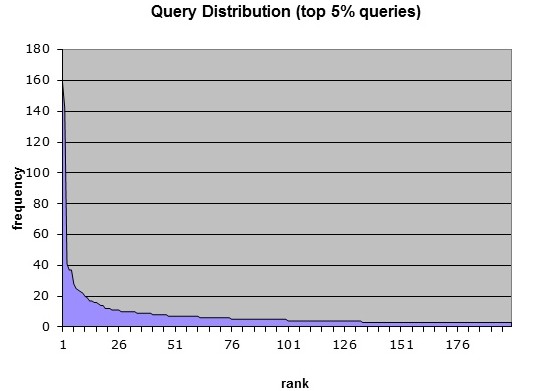
As you can see there is a “short head” of frequent search queries at our firms (like Shareholder Agreement or Confidentiality). It is here we can be creative with best bets functionality to ensure that the very best document gets returned when a frequent query is entered in the search box. But there is a truly long tail of unique and semi-unique queries at our firms too.
And as you may have experienced, the signal-to-noise ratio as you travel down this long tail just gets worse. Hence the need for filters. It is between the short head and the long tail where we turn to our search filters to help minimize all the noise. We choose the intersection of a set like Practice Group, Document Type, and perhaps by Date to shrink the number of results we need to trawl through.
“… the only way a [user] can maintain a consistently good enough signal to find what he or she wants is if the filters get increasingly powerful” – The Long Tail.
At our firms we employ a wide range of filters to help us maintain that good-enough signal to find what we need. Firstly we have DIY filters, where we use expertise already embedded into the system, such as:
– using a ‘Knowledge Resources’ tab. By searching a smaller bucket the noise has already been removed before you even begin your search. Some firms have gone a step further and created specific practice or transaction-type knowledge collections that make it an even smaller bucket.
– applying well-defined and powerful search filters. These help shrink the bucket after you’ve typed in your search.
– employing a well-designed combo of search and browse options to guide navigation behaviours. By applying metadata and other tools to increase the information scent, we can improve the findability of some of that long-tail knowledge.
And secondly we have Expert Network Filters, where we use the expert networks that we’re a part of to filter the noise of too many results. Here we might:
– get a Librarian to do the initial broad searches who send through an already filtered set of results.
– call the research lawyer or KM lawyer to point us in the right direction, and who often points us to either exactly the person we need to talk to or the exact set of documents we need.
– pop down the hall or reach out to other members of the firm that may have exactly the answer we’re looking for.
But as the firehose gets bigger, we will need increasingly more powerful filters to help us. I realize that my love-hate relationship with Twitter is largely because I have ineffective filters. I have various lists set up to help refine and break up the noise, but I still come away feeling overwhelmed by my streams full of interesting people, thoughts and links.
Likewise in our firms; Enterprise Search means we can search for everything that was ever written. Which is all well and good if you’re looking for the most popular (or most recent), but if you’re looking for anything in that middle bit, or in the tail, then we need to get much more creative with our filters. It might be the only way we can tackle this ever-lengthening tail of information overload, and avoid getting wet.
Comments are closed.